
Learn how to build your own custom text classification model with Lettria.
Model training is currently unavailable for self-serve users. In order to access it, reach out to a member of our team.
Select Your Data
The first step is to select your data.
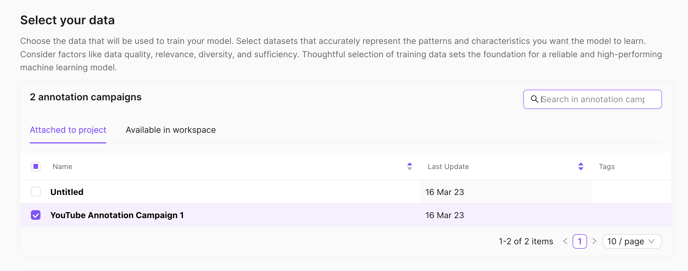
You can choose datasets that are either attached to the project you're in, or available in a workspace that you're a part of.
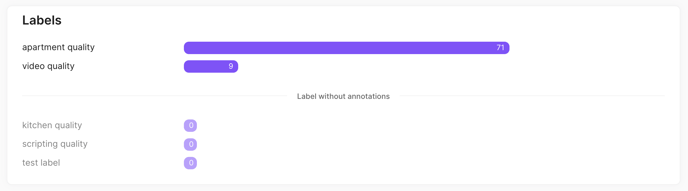
Below, you'll be able to visualise the annotations and labels in your dataset.
Select Your Method
There are two ways of training a classification model with Lettria.
Machine Learning
This is a machine-learning-based model training technique (also called AutoLettria).
It automatically learns patterns in your data, and the trained model can make predictions. It adapts to a large range of possibilities and exceptions.
However, in order to train a machine learning model, a lot of annotated data is required for an effective model.
Patterns
This is a pattern-based classification model training technique (also called Statator).
It always works well on the same data, and requires lesser data than for Machine Learning.
For advice on when to use what method, read our blog article here.
Split Your Data
Random Splitting

Per Campaign
If you created separate annotation campaigns to control the partition of your data into the three categories (training, validation and test), you can choose the "Per Campaign" option.
You need to choose at least 3 campaigns in 'Step 1: Select Your Data' to be able to choose this option.
Keep in mind that the only real reason not to use random (default) splitting is if you annotated dedicated training and evaluation datasets.
If your training type is Patterns, click 'Train →' to start model training.
If your training type is Machine Learning, go forward to 'Select Instance Type'.
Select Instance Type (for machine-learning only)
You can select the type of compute instance to use for your model training. There are two options available:
1. Regular
2. Fast
Advanced Settings (for machine-learning only)
For more control and advanced options, click on 'Advanced Settings'.
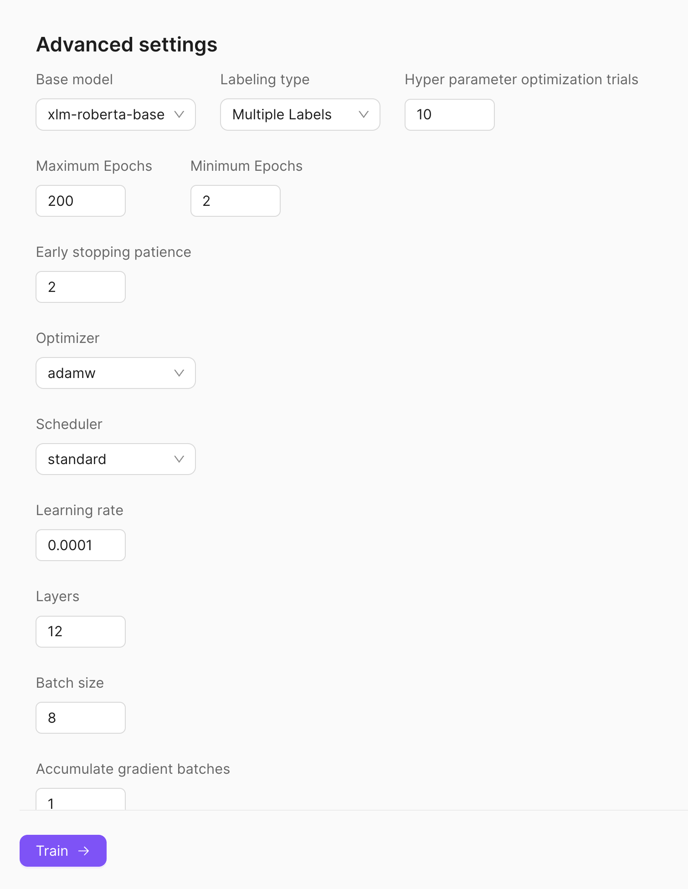
When you're done, click on 'Train →' to begin training.